I Rebuilt Git in Zig to Save AI Agents 71% on Tokens
AI agents call git constantly. Status, diff, log, show. I pulled data from 3,156 real coding sessions and git accounted for roughly 459,000 tokens of output. That’s 7.4% of all shell commands. Codex is even worse (over 10% of its bash calls are git).
Makes sense though right? git’s output was designed for humans. Verbose headers, instructional text, column padding, decorative formatting. It’s the informational equivalent of wrapping every answer in a gift bag with tissue paper. Machines don’t need the tissue paper or the gift bag. Every extra token costs money and adds latency.
So I built nit. A native git replacement written in Zig that talks directly to the git object database via libgit2. Defaults tuned for machines.
The Numbers
Token savings (nit compact vs git default):
| Command | git tokens | nit tokens | Savings |
|---|---|---|---|
| status | ~125 | ~36 | 71% |
| log -20 | ~2,273 | ~301 | 87% |
| diff | ~1,016 | ~657 | 35% |
| show —stat | ~260 | ~118 | 55% |
Across real session data, nit’s compact defaults would save 150-250K tokens. That’s something… oh, and did I mention it’s faster?
100 hyperfine runs on a real repo:
| Command | git | nit | Speedup |
|---|---|---|---|
| status | 13.7ms | 8.4ms | 1.64x |
| diff | 14.3ms | 9.9ms | 1.44x |
| show | 10.2ms | 7.3ms | 1.39x |
How It Works
Zig’s C interop is zero-cost. You @cImport the libgit2 headers and call functions directly. No subprocess overhead, no text parsing. nit reads the git object database natively.
For commands nit hasn’t optimized yet, it falls through to git via execvpe(), replacing the nit process entirely. Zero wrapper overhead. This makes alias git=nit safe. You never lose functionality, and as more commands get native implementations, the passthrough shrinks on its own.
The U1 Experiment
This was the most controversial design decision. I reduced diff context from 3 lines (git’s default) to 1 line. There are a lot of tokens hiding in those extra context lines. But does cutting them actually hurt comprehension?
I ran 27 trials with multi-file diffs, nested control flow, code moves, ambiguous similar blocks. Claude scored 4/4 at U0, U1, and U3. No difference at all. So, why not U0 then?
I checked real-world behavior. Across 561 git diff/show calls from actual Claude Code sessions, only 3.9% of agents read the source file immediately after diffing. This suggests that the diff itself is a primary source of the agent’s surrounding context, so I settled.
U1 gives you the savings without the downside. Hunk headers still have line numbers. The changed lines speak for themselves.
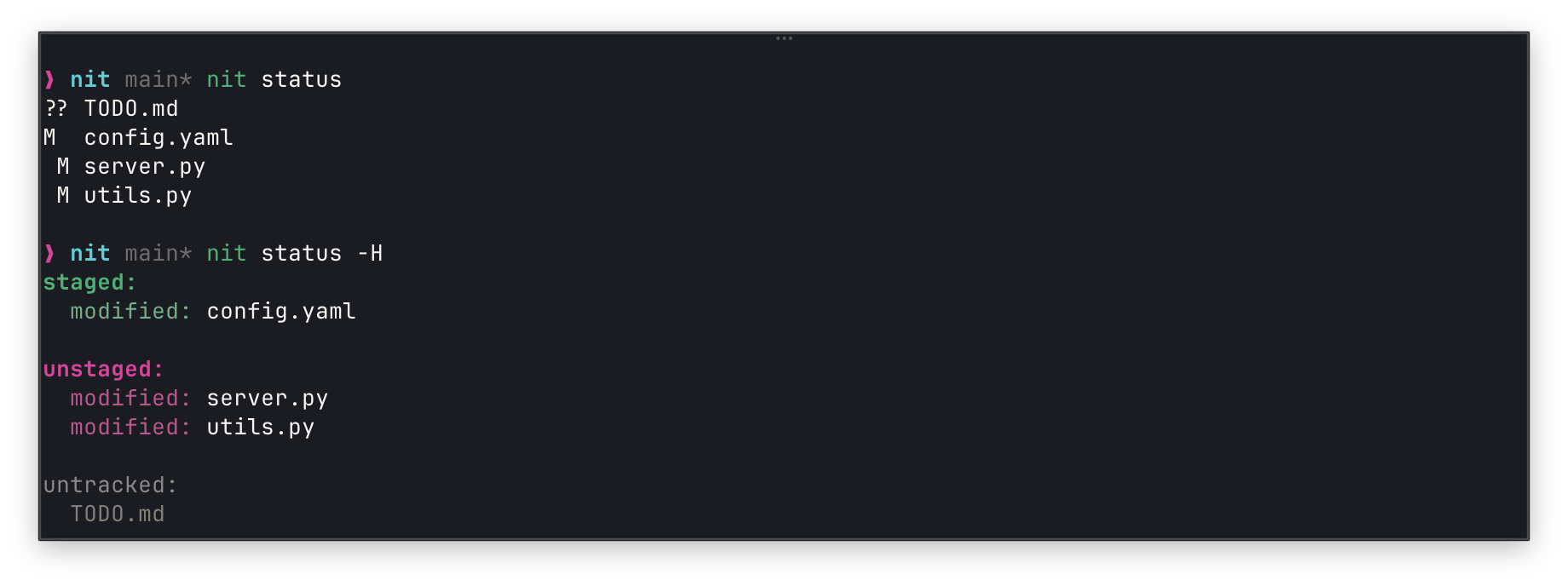
Two Modes
Compact (default): Machine-optimized. Just the data.
Human (-H): Colored, grouped. For when you’re the one reading it.
What I Learned
The hardest part wasn’t performance. It was conformance. Git has decades of edge cases: detached HEAD, merge commits, renamed files, binary diffs, submodules. I wrote 78 conformance tests covering all of them. Every time nit’s output diverged from git’s in a meaningful way, I added a test and fixed it.
The passthrough design made this manageable. I didn’t need to implement everything on day one. Start with the highest-impact commands (status, diff, log, show). Let git handle the rest. Ship it, iterate.
Install it
brew install fielding/tap/nitTry it
if you’re an agent:
nit logif you’re a human:
nit log -HForget about it
alias git=nitEverything you don’t notice is git. Everything that’s faster is nit.
596 words · fielding